병렬화된 병합정렬과 마이크로벤치마킹
이 글에서는 병합정렬 알고리즘에 병렬처리를 적용한 후 기대와는 다르게 성능이 느려지는 현상에 대해 이야기한다. 이야기 순서는 다음과 같다.
- 병합정렬 소개
- ForkJoinPool을 이용한 병렬화
- JUnit을 통한 성능 비교
- 병렬화된 코드가 느려진 이유 분석
- ForkJoin 마이크로벤치마킹 시 확인 사항
병합정렬 소개
병합정렬merge sort은 항상 O(n*log n)의 시간 복잡도를 가지는 정렬 알고리즘으로, 분할 정복divide and conquer 아이디어에 기반하고 있다. 정렬을 수행하는 방식은 다음과 같다.
- 정렬되지 않은 크기 N의 리스트를 반으로 나눈다divide.
- 이 과정을 N개의 리스트(각각의 크기는 1)가 만들어질 때 까지 반복한다.
- 쪼개진 리스트들을 2개씩 병합merge하여 정렬된 새로운 리스트로 만든다.
- 이 과정을 1개의 리스트가 만들어질 때 까지 반복한다.
그림으로 보면 다음과 같다.
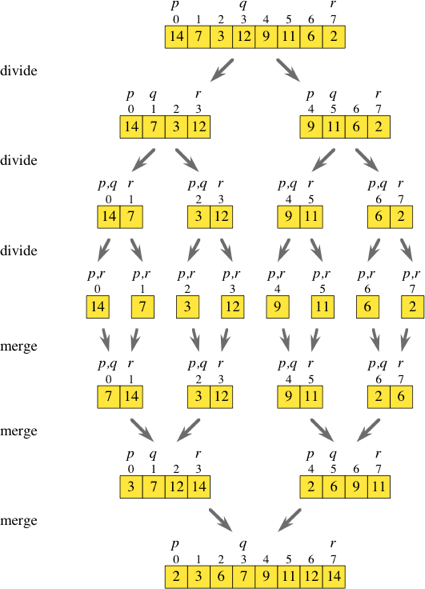
그림 1. 병합정렬 (출처: Overview of merge sort, Khan Academy)
Java로 작성한 코드는 다음과 같다.
public class MergeSort implements Sort {
public void sort(int[] input) {
log.info("merge-sort");
int[] result = new int[input.length];
divideSort(input, 0, input.length - 1, result);
}
private void divideSort(int[] input, int idxFrom, int idxTo, int[] result) {
if (idxTo - idxFrom < 1) {
return;
}
int idxMid = (idxTo + idxFrom) / 2;
divideSort(input, idxFrom, idxMid, result);
divideSort(input, idxMid + 1, idxTo, result);
merge(input, idxFrom, idxMid, idxTo, result);
set(result, input, idxFrom, idxTo);
}
private void merge(int[] input, int idxFrom, int idxMid, int idxTo, int[] result) {
int i = idxFrom, j = idxMid + 1;
for (int k = idxFrom; k <= idxTo; k++) {
if (i <= idxMid && (j > idxTo || input[i] < input[j])) {
result[k] = input[i++];
} else {
result[k] = input[j++];
}
}
}
private void set(int[] source, int[] target, int idxFrom, int idxTo) {
for (int i = idxFrom; i <= idxTo; i++) {
target[i] = source[i];
}
}
}전체 코드는 여기서 확인할 수 있다.
ForkJoinPool을 이용한 병렬화
병합정렬은 분할 정복 알고리즘에 기초하고 있으므로 병렬화parallelize가 그리 어렵지 않다. 이해를 돕고자 병렬화된 병합정렬을 의사 코드pseudo code로 작성하면 다음과 같다.
// 리스트 n에 대해 인덱스 값 p부터 q까지의 요소들을 정렬
algorithm sort(n, p, q) is
if s+1 < e then
return
r = (p + q) / 2
fork sort(n, p, r)
sort(n, r, q)
join
merge(n, p, r, q)리스트를 2개로 나누어 작업하는 부분을 병렬로 호출한 후, 작업이 완료되길 기다렸다가 병합을 진행하는 식이다. java.util.concurrent.ForkJoinPool과 java.util.concurrent.RecursiveAction를 사용하여 구현한 코드는 다음과 같다.
public class ParallelMergeSort implements Sort {
private static final ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
@Override
public void sort(int[] input) {
log.info("merge-sort-in-parallel");
int idxFrom = 0;
int idxTo = input.length - 1;
int[] result = new int[input.length];
forkJoinPool.invoke(new SortTask(input, result, idxFrom, idxTo));
}
private class SortTask extends RecursiveAction {
private int[] input;
private int[] result;
private int idxFrom;
private int idxTo;
SortTask(int[] input, int[] result, int idxFrom, int idxTo) {
this.input = input;
this.result = result;
this.idxFrom = idxFrom;
this.idxTo = idxTo;
}
@Override
protected void compute() {
if (idxTo - idxFrom < 1) {
return;
}
int idxMid = (idxTo + idxFrom) / 2;
SortTask left = new SortTask(input, result, idxFrom, idxMid);
SortTask right = new SortTask(input, result, idxMid + 1, idxTo);
left.fork();
right.compute();
left.join();
merge(input, idxFrom, idxMid, idxTo, result);
set(result, input, idxFrom, idxTo);
}
private void merge(int[] input, int idxFrom, int idxMid, int idxTo, int[] result) {
int i = idxFrom, j = idxMid + 1;
for (int k = idxFrom; k <= idxTo; k++) {
if (i <= idxMid && (j > idxTo || input[i] < input[j])) {
result[k] = input[i++];
} else {
result[k] = input[j++];
}
}
}
private void set(int[] source, int[] target, int idxFrom, int idxTo) {
for (int i = idxFrom; i <= idxTo; i++) {
target[i] = source[i];
}
}
}
}전체 코드는 여기서 확인 가능하다.
JUnit을 통한 성능 비교
순차적 병합정렬과 병렬화된 병합정렬의 속도 비교를 위해 간단한 단위 테스트를 만들었다.
@RunWith(value = Parameterized.class)
public class MergeSortTest<T extends Sort> {
private T sort;
private Class<T> sortClass;
private static final int[] list;
private static final int LIST_SIZE = 10000;
static {
list = new int[LIST_SIZE];
for (int i = 0; i < list.length; i++) {
list[i] = new Random().nextInt(10000);
}
}
public MergeSortTest(Class<T> sortClass) {
this.sortClass = sortClass;
}
@Parameterized.Parameters
public static List<Class> sortClasses() {
List<Class> classes = new ArrayList<>();
classes.add(ParallelMergeSort.class);
classes.add(MergeSort.class);
return classes;
}
@Before
public void setup() throws IllegalAccessException, InstantiationException {
this.sort = sortClass.newInstance();
}
@Test
public void sort() throws Exception {
new ParallelMergeSort().sort(list);
}
}전체 코드는 여기서 확인 가능하다.
수행 결과는 어떨까? Junit 테스트 결과를 보도록 하자.
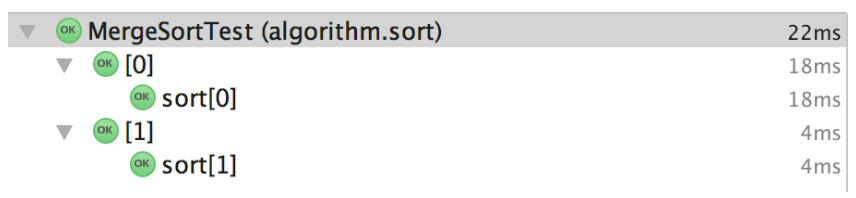
그림 2. 순차적 병합정렬과 병렬화된 병합정렬의 테스트 결과
[0]과 [1]은 각각 병렬 병합정렬과 순차 병합정렬이다. 이상하게도 병렬 버전이 수행 속도가 더 길다. CPU를 동시에 더 많이 쓸 수 있는 만큼 더 빨라야 하는 것 아닌가? 왜 이런 결과가 나오는 걸까?
느려진 이유
일단 병렬 버전에서 스레드가 더 많이 쓰이는지 확인해 봤다. 병합정렬 병렬 버전과 순차 버전을 함께 테스트 할 때의 스레드 개수는 아래 그림과 같이 변화한다.
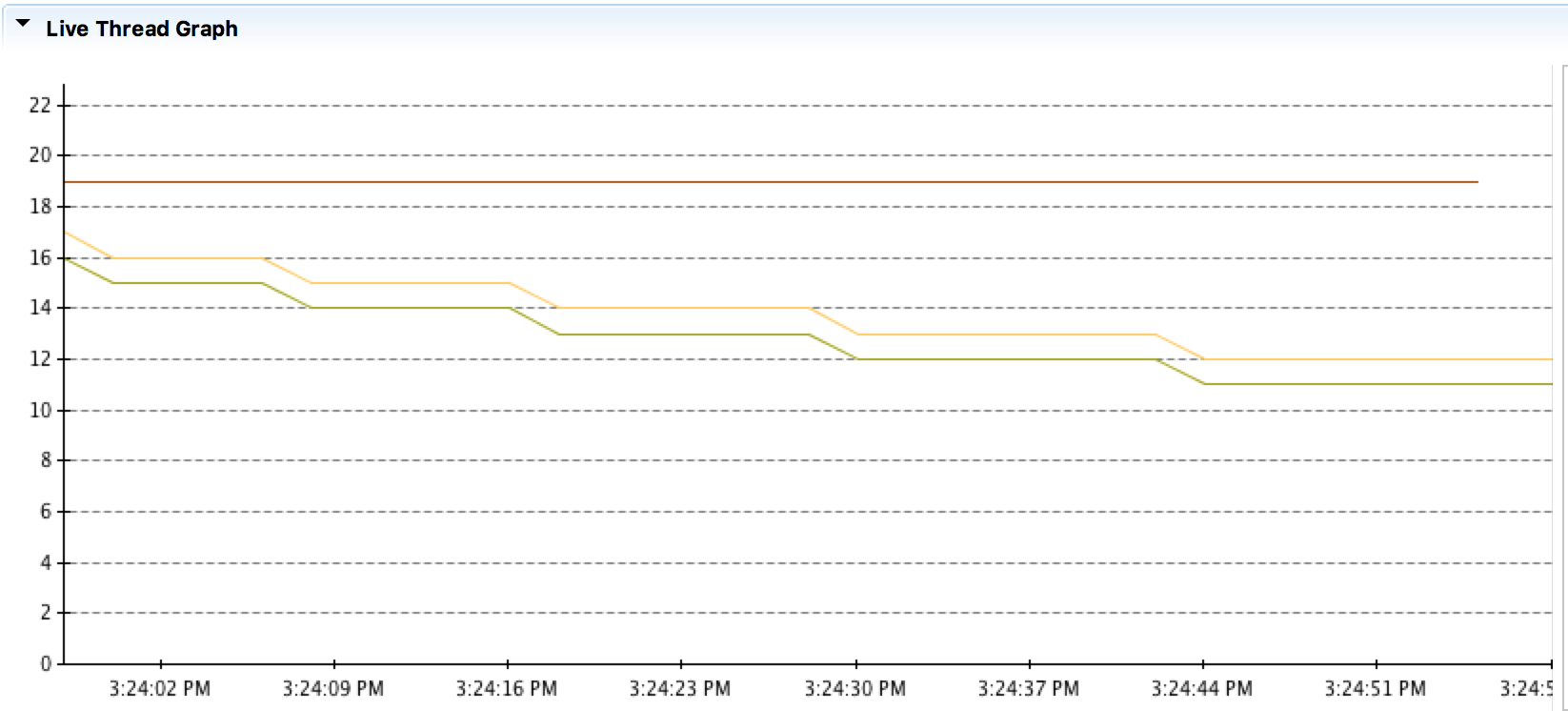
그림 3. 병합정렬 병렬 버전과 순차 버전을 함께 실행했을 때의 스레드 개수
처음에는 병렬 버전이 실행된 것이고 이후에 순차 버전이 실행되는 데 점점 스레드의 개수가 줄어든다. 이는 ForkJoinPool 스레드가 사용되다가 순차 버전에서 쓰이지 않아 제거되어 생긴 변화이다. 실제로 병렬 버전에서는 아래와 같이 ‘ForkJoinPool.commonPool-worker-숫자’스레드가 살아 있지만, 순차 버전에서는 볼 수 없다.
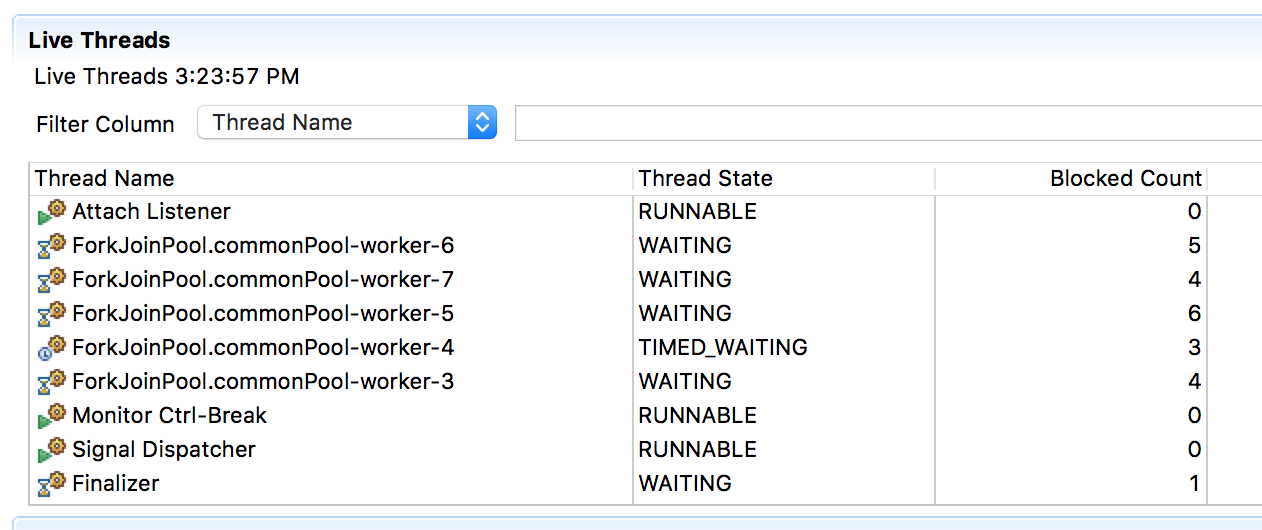
그림 4. ForkJoinPool을 사용할 때의 스레드 모습
이번에는 병합정렬이 수행될 때 어디서 시간이 많이 소요되는지를 확인해 봤다. 아래 그림은 전체 수행 시간을 ‘interval’이라는 항목에, 가장 많은 실행 시간이 소요된 패키지 및 클래스를 ‘Hot Packages’와 ‘Hot Classes’라는 항목에 보여주고 있다.
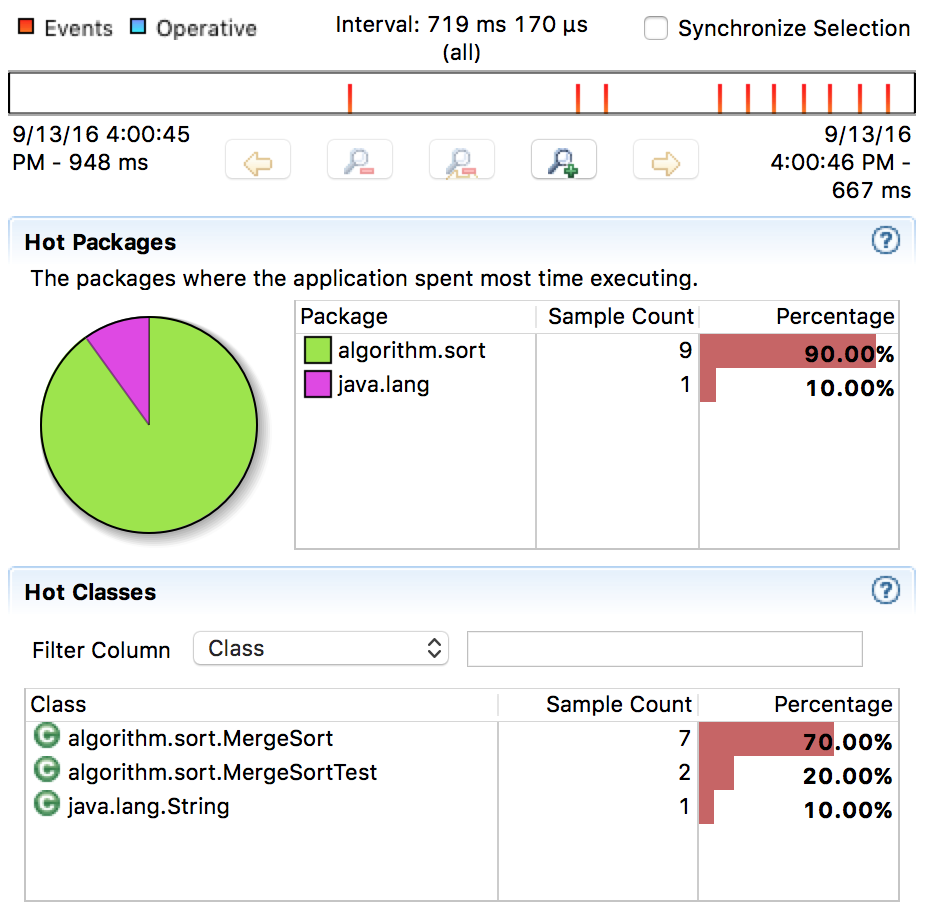
그림 5. 순차 병합정렬의 코드 수행 시간
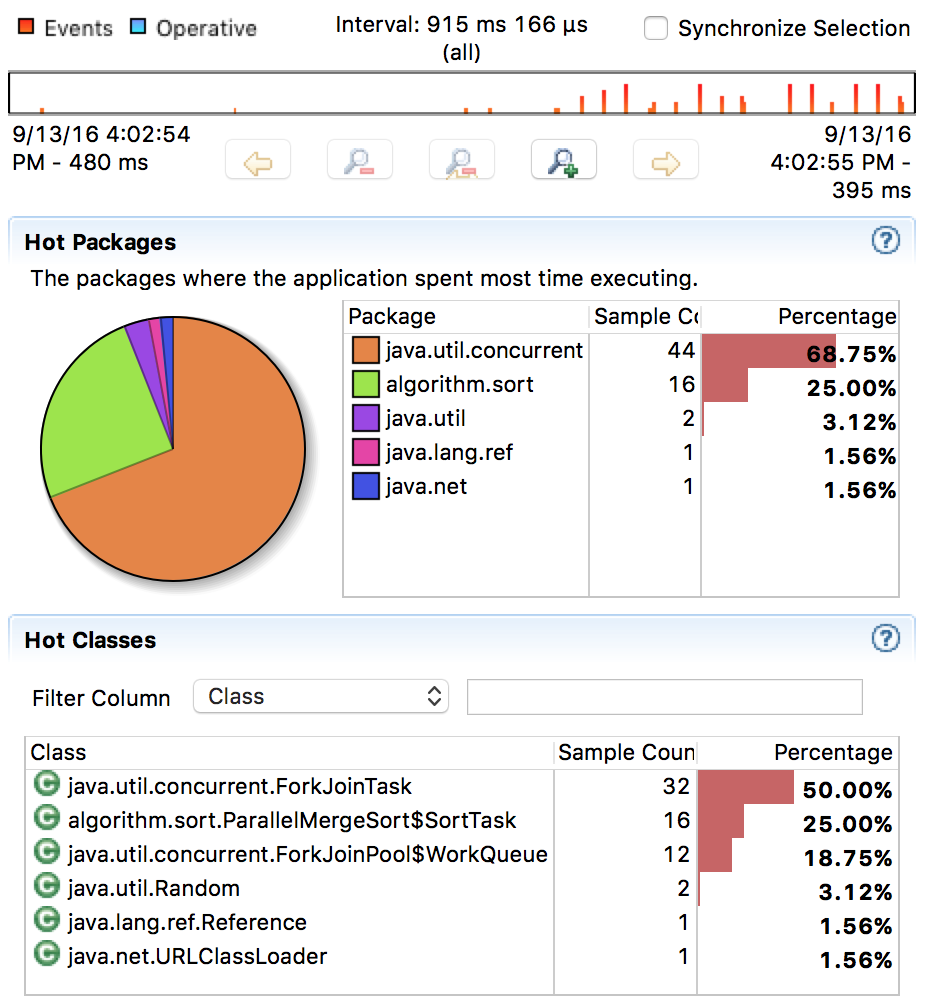
그림 6. 병렬 병합정렬의 코드 수행 시간
순차 병합정렬의 코드 수행 시간을 보면 약 70%가 순수한 알고리즘을 수행시간이다. 한편, 병렬 버전에서는 단지 25% 정도만이 알고리즘 수행시간이다. 이보다 더 많은 수행 시간을 차지하는 것은 java.util.concurrent 패키지의 ForkJoin이며, 약 68%라는 적지 않은 수치를 나타낸다. 전체 수행시간이 915ms이니 약 630ms가 ForkJoin에 사용된 것이다. 5개의 스레드가 ForkJoin에 동시에 사용되었다고 해도 결코 무시할 수 없는 시간이다.
이를 바탕으로 병렬화된 알고리즘의 수행 시간을 더 빠르게 할 수 있는 방법을 생각해 볼 수 있다. ForkJoin의 수행 시간이 순수 알고리즘의 수행 시간 비교에 영향을 미치지 못할 정도로 작은 비중을 차지하도록 하면 된다. 예를 들어, 정렬 대상 리스트의 수를 늘려보거나 정렬을 위해 분할된 작업의 수행 시간을 늘려보면 병렬화된 알고리즘의 수행 시간이 더 빨라지는 지점을 만날 수 있다.
ForkJoin 마이크로벤치마킹 시 확인 사항
마지막으로, Dan Grossman의 Beginner’s Introduction to Java’s ForkJoin Framework의 일부 내용을 소개하고자 한다. 여기서는 병렬화된 코드의 마이크로벤치마킹microbenchmarking 결과가 순차 버전에 비해 더 나은 속도를 내지 못할 경우 확인해 볼 만한 목록을 제공하고 있다.
- 충분히 긴 시간Time for long enough
- 충분한 데이터 요소들Have enough data elements
- 예상 개수만큼 프로세서가 사용 가능한지 확인Make sure you have the number of processors you think you do
- 라이브러리의 준비 운동Warm up the library
- 개별 요소에 대한 충분한 계산Do enough computation on each element
- 연산 결과의 사용Use the result of your computation
- 단순한 입력값 지양Do not use very simple inputs
- 매 반복마다 약간씩 다른 입력값 사용Use slightly different inputs for each iteration
- 순차적 종료부 재확인Double-check your sequential cut-offs
1~5번 항목부터 간단히 살펴보자. 제대로 된 ForkJoin 마이크로벤치마킹을 위해서는 수행 시간이 적어도 몇 초 이상 되어야 하며, 데이터 요소는 적어도 백만 개 이상 되어야 한다. ForkJoinPool 생성자에 지정할 수 있는 프로세서의 개수도 확인해야 한다. ‘라이브러리의 준비 운동’이라고 함은 코드가 최적화하는 데 시간이 필요하므로 벤치마킹 이전에 fork-join 연산을 여러 차례 수행해 보라는 이야기이다. 또한 각 요소에 대해 너무 단순한 연산은 피해야 한다.
6~8번 항목은 모두 같은 맥락의 이야기이다. 컴파일러의 최적화 작업으로 인해 성능 측정이 잘못될 수 있으니, 연산 결과는 실제 사용되어야 하고, 단순한 입력값은 피해야 하며, 매 반복의 입력값이 같으면 안된다.
마지막으로 ‘순차적 종료부 재확인Double-check your sequential cut-offs‘은 용어가 어색한데 설명을 들으면 어렵지 않다. 분할된 작업(위에서 소개된 코드 상에서는 RecursiveAction의 구현체를 가리킴)의 단위가 너무 작거나 크면 안된다는 이야기이다. 너무 작을 경우 작업을 생성하는 데 부하가 생겨 fork-join 코드가 느려지고, 너무 클 경우 프로세서가 유휴 상태로 있는 시간이 많아지기 때문이다.
결론
코드를 개선하고 성능이 얼마나 빨라졌는지를 예상하는 일은 쉽지 않다. 단순히 병렬 처리를 적용했다고 가용한 CPU 사용수 만큼 속도가 빨라지지 않는 것처럼 소프트웨어에는 쉽게 파악하기 힘든 복잡성이 자리잡고 있다. 혹자는 이런 부분이 과학적이기보다는 예술적인 부분에 가깝다고 표현하며 결국 적절한 테스트가 필요하다고 주장한다. 지금까지 살펴 본 내용들이 소프트웨어 개발에 있어 직접적인 도움을 주지는 않을지도 모른다. 누군가에게는 평생 쓸 일이 없는 지식일 수도 있다. 그러나 적어도 성능 비교를 위해 테스트가 필요하다면 좀 더 올바른 결정을 내리는 데 도움이 되지 않을까.
© 2020 codehumane ― Powered by Jekyll and Textlog theme