Martin Fowler - Refactoring a JavaScript video store 부분 번역
한동안 바쁘다는 핑계로 잠시 블로그를 멈췄는데, Martin Fowler 아저씨의 Refactoring a JavaScript video store을 번역하는 것으로 다시 시작해보려 한다. 모든 내용을 번역한 것은 아니고 Comparing the approaches 부분만을 작업했다. 전체 내용을 정리하는 이 부분이 생각할 거리가 가장 많아서, 차근 차근 살펴보고 싶었기 때문이다. 자, 시작해보자.
각각의 접근법 비교
지금까지 언급한 내용을 다시 한 번 살펴보자. 맨 처음 코드는 하나의 인라인inline 함수로만 이루어져 있었다. 이 코드를 리팩토링하여 HTML 렌더링도 가능하도록 하되, 계산 코드의 중복은 피하고 싶었다. 코드를 여러 개의 함수로 나누는 것을 시작으로(하지만 이 함수들은 여전히 원래의 함수 안에 위치했다), 서로 다른 4가지 방식으로 접근해 보았다.
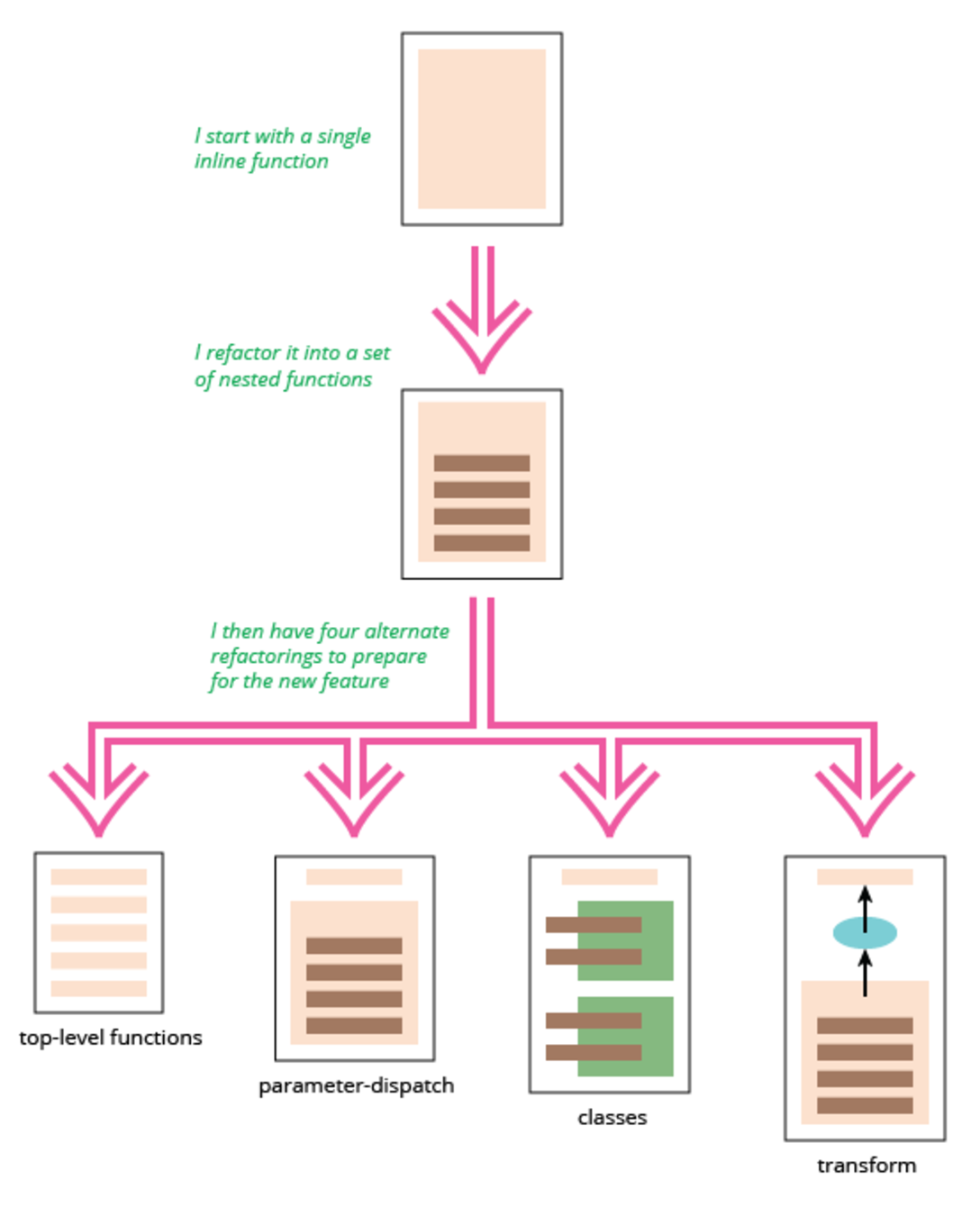
이미지1. 초기 단계 및 4가지 접근법 요약 그림 (출처 - Refactoring a JavaScript video store)
// top-level-functions
// 모든 함수를 최상위 레벨 함수로 작성
function htmlStatement(customer, movies)
function textStatement(customer, movies)
function totalAmount(customer, movies)
function totalFrequentRenterPoints(customer, movies)
function amountFor(rental, movies)
function frequentRenterPointsFor(rental, movies)
function movieFor(rental, movies)
// parameter-dispatch
// 반환값 형태를 알려주는 파라미터를 최상위 함수에 사용함
function statement(customer, movies, format)
function htmlStatement()
function textStatement()
function totalAmount()
function totalFrequentRenterPoints()
function amountFor(rental)
function frequentRenterPointsFor(rental)
function movieFor(rental)
// classes
// 계산 로직(렌더링 함수에서 사용될)을 클래스로 이동함
function textStatement(customer, movies)
function htmlStatement(customer, movies)
class Customer
get amount()
get frequentRenterPoints()
get rentals()
class Rental
get amount()
get frequentRenterPoints()
get movie()
// transform
// 계산 로직을 서로 독립된 내장 함수(렌더링 함수에게 중간 데이터 구조체를 제공하는)로 나눔
function statement(customer, movies)
function htmlStatement(customer, movies)
function createStatementData(customer, movies)
function createRentalData()
function totalAmount()
function totalFrequentRenterPoints()
function amountFor(rental)
function frequentRenterPointsFor(rental)
function movieFor(rental)
*각각의 코드 보기
개념적으로 간단했던 top-level-functions 예제를 시작으로 각각의 접근법들을 비교해 보자. top-level-functions가 간단한 이유는 코드가 순수한 함수들로 이루어져 있고, 각각은 코드 어디에서나 호출될 수 있기 때문이다. 사용하기도 쉽고 테스트하기도 쉽다(테스트 케이스나 REPL을 통해 개별 함수들을 쉽게 테스트할 수 있다).
여기서 top-level-functions이란, 각 함수들이 서로에게 속하지 않고 독립적으로 선언되어 있음을 가리킨다. 누구에게도 속하지 않으므로 최상위 레벨로 함수들이 선언되어 있다.
– 역자주
top-level-functions의 단점은 반복적으로 파라미터를 넘겨야 하는 일이 많다는 점이다. movies 데이터 구조체를 모든 함수들이 넘겨 받아야 하고, customer를 넘겨 받아야 하는 함수들도 꽤 있다. 반복적인 작성을 걱정하는 것이 아니다. 반복적인 읽기를 걱정하는 것이다. 파라미터를 읽을 때 마다 이것이 무엇인지 이해해야 하고 값의 변경도 추적해야 한다. customer와 movies 데이터를 공통된 컨텍스트로 가지는 함수들이 있지만, top-level-functions에서는 이러한 컨텍스트가 분명하게 드러나지 않는 것도 문제이다. 코드를 읽을 때 이를 추론하고 어떻게 실행될지 마음속으로 그려볼 수 있긴 하다. 그러나 개인적으로는 가능한 명시적인 것을 선호한다.
컨텍스트가 커질 수록 이 요소는 더욱 중요해진다. 여기서는 단지 2개의 데이터 항목뿐이지만, 얼마든지 더 많은 데이터가 있는 경우를 만날 수 있다. top-level-functions은 모든 호출이 많은 파라미터를 가지게 했고 이는 결국 이해를 더디게 만들었다. 간혹 모든 파라미터들을 하나의 컨텍스트 파라미터(여러 함수들을 위해 모든 컨텍스트를 담는)로 묶는 실수를 범하기도 하는데, 이는 함수들이 하는 일을 모호하게 만들 뿐이다. local partially-applied functions을 사용하여 이런 고통들을 줄일 수는 있지만 클라이언트 코드에 일정량의 중복(부가적인 함수들을 선언해야 하는)을 안겨주게 된다.
local partially-applied functions란, 전역 함수의 일부 혹은 전체 파라미터를 미리 채워놓고 호출하는 지역 함수를 가리킨다. 여기 코드를 보면 단번에 이해할 수 있을 것이다.
– 역자주
나머지 3개의 접근법들이 가지는 장점은 공통된 컨텍스트가 명시적으로 드러난다는 점이다. parameter-dispatch 방식에서는 최상위 함수의 파라미터 목록에서 이 컨텍스트가 포착된다. 이 파라미터들은 내장된 함수들에 공통된 컨텍스트로 사용된다. 하나의 함수로 되어 있던 원래의 코드를 내장된 함수로 리팩토링함으로써 가능한 결과이며, 내장된 함수를 지원하지 않는 언어에 비해 보다 간단한 방법이다.
하지만 parameter-dispatch 접근법은 html 형태의 응답과 같이 전반적으로 다른 행위가 필요한 경우에는 흔들리기 시작한다. 어떤 함수를 실행시킬지 결정해야 하는 새로운 종류의 디스패처dispatcher를 작성해야 한다. 렌더러renderer에게 형태를 명시해 주는 것이 그리 나쁜 것은 아니지만, 이러한 디스패치dispatch 로직은 분명한 냄새이다. 이름 있는 함수를 호출할 수 있는 언어의 핵심 기능을 중복시키기 때문이다. 결국 아래와 같은 코드가 만들어졌다.
function executeFunction (name, args) {
const dispatchTable = {
//...
이런 접근법이 필요한 상황도 있다. 출력 형태의 결정이 호출자에게 데이터로써 전달되는 경우이다. 이 때는 디스패치 메커니즘이 의미가 있다. 그러나 호출자가 단지 함수호출을 다음과 같이 하고 있다면…
const someValue = statement(customer, movieList, 'text');
…그렇다면 코드에서 디스패치 로직을 작성할 이유는 없다.
여기서는 호출 메소드가 핵심이며, 함수를 선택하도록 가리키는 리터럴 값은 냄새이다. 이런 API 대신, 호출자가 무엇을 원하는지를 함수의 이름(textStatement 혹은 htmlStatement)을 통해 말하도록 하라. 이렇게 하면 언어 차원의 함수 디스패치 메커니즘을 사용할 수 있고, 새로운 것을 조잡하게 추가하지 않아도 된다.
자, 필자는 위 2가지 접근법 중 어느 것을 선호할까? 개인적으로는 로직을 위한 공통 컨텍스트가 분명하게 드러나는 것이 좋다. 그러나 그 로직으로 서로 다른 연산을 호출할 수 있어야 한다고 생각한다. 이런 필요가 느껴지면 곧바로 객체 지향(근본적으로 개별적 호출이 가능한 작업들의 집합이고 이 작업들이 공통 컨텍스트를 잘 포착하기 때문)이 떠오른다. 이것이 class 버전의 예제를 작성하게 된 이유이고, 이 예제에서는 customer와 movies라는 공통 컨텍스트가 customer와 rental 객체들에게서 잘 포착되고 있다. 객체들을 초기화할 때 설정된 이 컨텍스트는 이후의 모든 로직에서 활용될 수 있다.
객체 메소드는 top-level-functions에서 다룬 local partially-applied functions와 유사하다. 생성자에 의해 공통 컨텍스트가 제공된다는 점을 제외하고 말이다. 따라서 최상위top-level 함수가 아닌, 지역 함수local function만을 작성한다. 호출자는 생성자로 컨텍스트를 명시한 뒤 직접 지역 함수를 호출한다. 객체 인스턴스의 공통 컨텍스트를 공유하는 지역 메소드들은, top-level functions에서의 파셜 어플리케이션partial application이라고 볼 수 있다.
여기서 말하는 지역 함수local function는 문맥상 클래스에 선언된 인스턴스 메소드를 가리킨다. JavaScript로 작성된 예제이므로 프로토타입 함수prototype function 용어를 사용했으면 어땠을까 싶다.
– 역자주
파셜 어플리케이션partial application이란, 함수를 호출하기 전에 미리 인자를 채워넣은 것을 가리키며 존 레식John Resig은 이를 설명하는 문서에서 아래와 같은 예제를 소개하고 있다.
– 역자주
String.prototype.csv = String.prototype.split.partial(/,\s*/);
클래스의 사용은 또다른 생각을 하게 만들어 주었는데, 바로 계산 로직으로부터 렌더링 로직을 분리하는 것이다. 원래의 단일 함수가 가지는 문제 중 하나는 이 두 로직이 섞여 있다는 점이다. 함수들을 쪼개면 어느 정도 분리가 가능하지만 개념적으로는 여전히 같은 공간에 위치한다. 이는 다소 부당한 처사이며, 계산 로직과 렌더링 함수를 각각 서로 다른 파일에 두고 import 문장을 통해 적절히 연결해 줄 수도 있다. 하지만 필자는 공통 컨텍스트를 보며 로직을 어떻게 모듈로 그룹화할지에 대해 새로운 아이디어를 떠올렸다.
필자가 객체들을 공통의 파셜 어플리케이션partial application 집합으로 묘사했지만, 이들을 다르게 바라볼 수도 있다. 객체들은 초기화될 때 입력 데이터 구조체를 받고, 계산 함수를 통해 가공된 형태로 외부에 제공한다. 이들 게터getter를 만들면서 이런 식의 생각은 점점 강해졌고, 클라이언트에서는 접근자를 통해 얻는 데이터를 가공되지 않은 데이터와 완전히 동일하게 다루게 되었다. 마치 Uniform Access Principle가 적용된 것과 같다. 이는 생성자의 인자들이 게터getter의 가상 데이터 구조체로 변환된 것으로 볼 수 있다. transform 예제가 바로 이 개념인데, 다만 초기 데이터들과 계산된 데이터들을 결합하여 새로운 데이터 구조체를 만들도록 구현되었다. 객체들이 customer와 rental 클래스에 계산 로직을 캡슐화 했던 것처럼, transform에서는 로직을 createStatementData와 createRentalData에 캡슐화 한다. 단순한 리스트와 해시List And Hash 데이터 구조체를 변환하는 이 접근법은 많은 함수형 사고에서 나타나는 특징이다. 이로 인해 create...Data 함수들은 필요로 하는 컨텍스트를 공유할 수 있고, 렌더링 로직은 여러 출력값들을 간단한 방법으로 이용할 수 있게 된다.
클래스를 transform으로 바라보는 것과 transform을 그 자체로 바라보는 것 사이의 한 가지 작은 차이점은 변환 연산이 일어나는 시점이다. transform 접근법에서는 변환 작업들이 한 번에 일어나는 반면, 클래스에서는 각 호출 시 마다 개별적으로 변환이 일어난다. 이 연산 시점은 쉽게 변경할 수 있다. 클래스의 경우에는 모든 연산을 생성자에서 한 번에 할 수 있다. transform의 경우에는 중간 데이터 구조체 안에서 함수를 반환함으로써 호출 시점에 연산이 일어나도록 할 수 있다. 이 예제에서는 성능 차이가 유의미 하지 않지만, 함수가 비용이 크다면 필자는 메소드/함수 호출의 결과를 캐시해서 사용하곤 한다.
이제 4가지 접근법 모두를 살펴보았다. 필자는 어느 것을 선호하는가? 개인적으로 디스패처 로직을 작성하는 것을 좋아하지 않기 때문에, parameter-dispatch 접근법은 사용하지 않는다. top-level-functions는 고민해볼 만하지만, 공유되는 컨텍스트가 커질수록 사용하고 싶은 마음은 급격히 사라진다. 인자가 2개만 되어도, 나머지 2개의 접근법을 선호하게 된다. 클래스와 transform 사이에서 선택하는 것은 어렵다. 공통 컨텍스트를 명시적으로 만들어주고 관심사를 잘 분리시켜주기 때문이다. 이를 가지고 싸우고 싶지는 않으며, 아마도 동전 뒤짚기를 하여 선택을 하게 될 것 같다.
© 2020 codehumane ― Powered by Jekyll and Textlog theme