TIL 2020 3Q
07/05
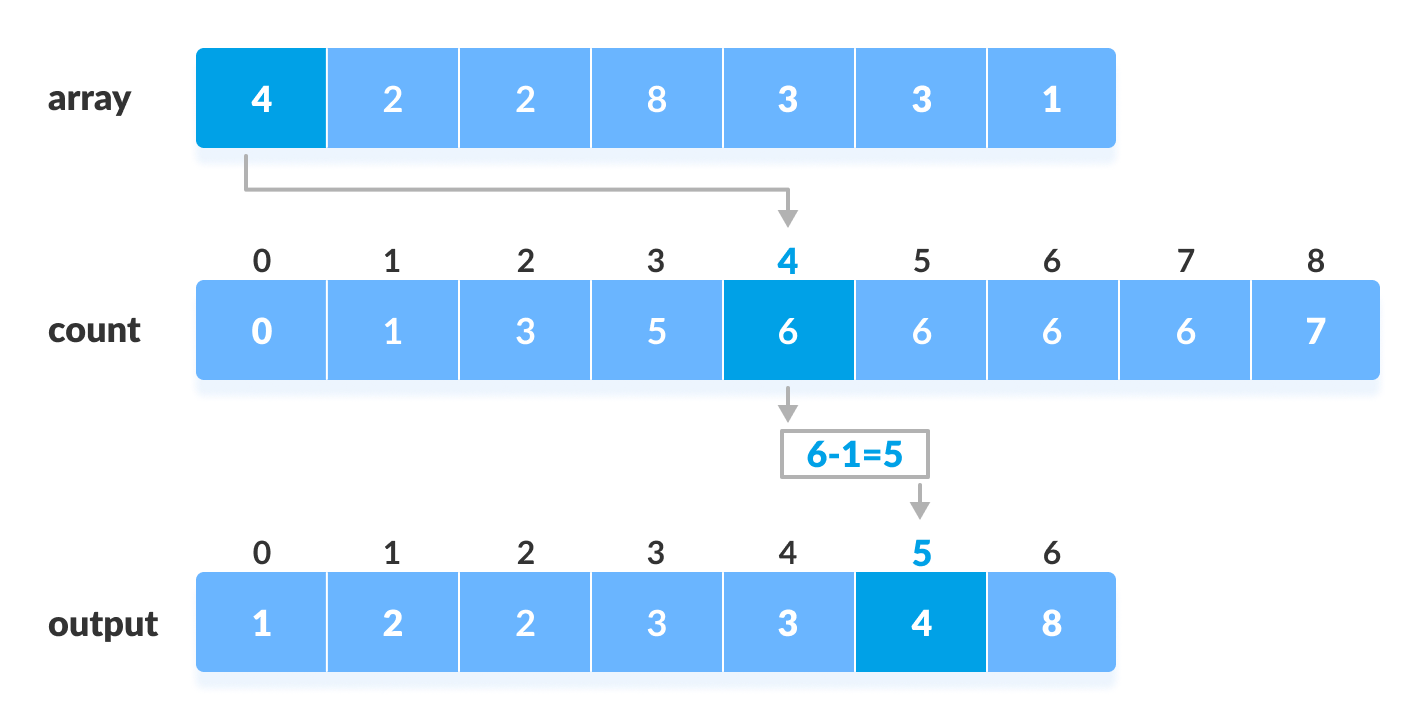
계수 정렬(counting sort)
HackerRank의 Fraudulent Activity Notifications 문제의 성능 개선 풀이를 보니, 계수정렬(counting sort)이 나오길래 간단히 정리. 내용은 Counting Sort Algorithm을 보고 기록.
- 일단, 주어진 배열에서 가장 큰 값을 찾는다.
- 그리고 이 값을
max라고 하자. max + 1크기의 배열을 생성.- 이 때, 원소의 초기 값들은 0으로 지정.
- 원소의 값을 배열의 인덱스로 하여, 각 원소의 발견 횟수를 배열에 저장. counting array가 된 것.
- 마지막으로, 배열을 왼쪽에서부터 누적 합으로 치환.
- 이제 원래 배열의 특정 원소 값이 몇 번째로 작은 값인지 구할 수 있다.
- 배열 원소의 값을 인덱스로 하여 counting array의 값을 구하고 여기서 1을 빼면 됨.
여기에 간단히 구현해 봄. 아래 그림도 함께 참고.
HackerRank
- Sorting: Bubble Sort 풀이 추가.
- 다음으로 Fraudulent Activity Notifications의 N·log(d) 구현.
- 이를 O(N·d) 혹은 O(N)으로의 개선.
- 개선 버전은 여기 풀이를 참고 했음.
07/06
Min Stack
Design and Implement Special Stack Data Structure, Added Space Optimized Version
push,pop,isEmpty,isFull연산과 더불어, 최소 엘리먼트를 반환하는getMin연산까지 지원하는 스택을 구현하라. 이 연산들은 모두 O(1)이어야 함. 구현 시에는 일반적인 스택 데이터 구조만 사용해야 함. 배열이나 리스트 등의 추가적인 데이터 구조체는 사용 X.
구현은 간단.
/**
* 연산 | 스택 | 부가스택
* push | 10 | 10
* push | 10,20 | 10,10
* push | 10,20,30 | 10,10,10
* push | 10,20,30,5 | 10,10,10,5
* pop | 10,20,30 | 10,10,10
*/
class SpecialStack {
private val original: Deque<Int> = ArrayDeque<Int>()
private val minimum: Deque<Int> = ArrayDeque<Int>()
fun push(element: Int) {
original.push(element)
minimum.push(determineMinimum(element))
}
private fun determineMinimum(element: Int): Int {
if (minimum.isEmpty()) {
return element
}
return min(
minimum.peek(),
element
)
}
fun pop(): Int {
minimum.pop()
return original.pop()
}
fun min(): Int {
return minimum.peek()
}
}
07/07
AMQP
07/12
HackerRank
- Merge Sort: Counting Inversions
- 이름 자체가 병합정렬이라, 이를 이용하여 구현.
- 병합정렬과 크게 다를 바 없음.
- 병합정렬하면 아래와 같은
21312회문순열 수가 떠오름.
21312
/ \
213 12
/ \ / \
21 3 1 2
/ \ | | |
2 1 3 1 2
\ / | \ /
12 3 12
\ / |
123 12
\ /
11223
07/14
AMQP - Publisher Confirms
Introducing Publisher Confirms
- 메시지 유실을 막는 한 가지 방법.
- 전통적 방법으로는 트랜잭션이 있음.
- 하지만 이는 블럭킹.
- 그리고 매번 커밋할 때마다 무거운
fsync()가 호출. (fsync) - 결국, 너무 느림.
- 트랜잭션 사용하는 코드는 아래와 같음.
Connection conn = connectionFactory.newConnection();
Channel ch = conn.createChannel();
ch.queueDeclare(QUEUE_NAME, true, false, true, null);
ch.txSelect();
for (int i = 0; i < MSG_COUNT; ++i) {
ch.basicPublish(
"",
QUEUE_NAME,
MessageProperties.PERSISTENT_BASIC,
"nop".getBytes()
);
ch.txCommit();
}
ch.close();
conn.close();
- 채널을 confirm mode로 사용하면,
- 브로커가 메시지를 처리할 때 메시지에 대한 confirm을 수행.
- 이는 비동기. 브로커를 기다리지 않아도 됨.
- 또한, 브로커는 디스크 쓰기를 일괄로 처리(효과적)할 수 있음.
- com.rabbitmq.client.impl.ChannelN을 보면 코드를 확인할 수 있음.
/** Set of currently unconfirmed messages (i.e. messages that have
* not been ack'd or nack'd by the server yet. */
private final SortedSet<Long> unconfirmedSet =
Collections.synchronizedSortedSet(new TreeSet<Long>());
/** Public API - {@inheritDoc} */
@Override
public void basicPublish(String exchange, String routingKey,
boolean mandatory, boolean immediate,
BasicProperties props, byte[] body)
throws IOException
{
if (nextPublishSeqNo > 0) {
unconfirmedSet.add(getNextPublishSeqNo());
nextPublishSeqNo++;
}
// ...
}
private void handleAckNack(long seqNo, boolean multiple, boolean nack) {
if (multiple) {
unconfirmedSet.headSet(seqNo + 1).clear();
} else {
unconfirmedSet.remove(seqNo);
}
synchronized (unconfirmedSet) {
onlyAcksReceived = onlyAcksReceived && !nack;
if (unconfirmedSet.isEmpty())
unconfirmedSet.notifyAll();
}
}
- 내부 동작 설명도 잘 나와 있음.
confirm.select메서드를 통해 채널의 publisher confirm을 활성화.- 활성화 되면
confirm.select-ok응답. - 이 때부터 퍼블리셔와 브로커는 퍼블리시에 대해 채번 시작.
- 그리고 퍼블리서는
basic.ack메서드를 받음. - 여기의
delivery-tag필드가 confirmed message의 번호. - 브로커가 메시지를 접수(acknowledges)하면 퍼블리셔에게 이를 알림.
- un-routable mandatory 또는 immediate 메시지는
basic.return후 바로 confirmed. - transient 메시지는 enqueued 시점에 confirmed.
- persistent 메시지는 디스크 영속이 되거나 모든 큐에 컨슘되면 confirmed.
- 아래의 몇 가지 주의점도 언급.
There are some gotchas regarding confirms. Â Firstly, the broker makes no guarantees as to when a message will be confirmed, only that it will be confirmed. Â Secondly, message processing slows down as un-confirmed messages pile up: the broker does several O(log(number-of-unconfirmed-messages)) operations for each confirm-mode publish. Â Thirdly, if the connection between the publisher and broker drops with outstanding confirms, it does not necessarily mean that the messages were lost, so republishing may result in duplicate messages. Lastly, if something bad should happen inside the broker and cause it to lose messages, it will basic.nack those messages (hence, the handleNack() in ConfirmHandler).
https://www.rabbitmq.com/amqp-0-9-1-reference.html#basic.publish.mandatory
07/17
Distributed locks with Redis #1
https://redis.io/topics/distlock
Redlock이라 불리는 알고리즘의 제안.
- 기존의 DLM (Distributed Lock Manager) 구현체들의 한계 때문.
- 서로 다른 접근법을 취하고, 쉬운 접근법으로 인해 다소 약한 보장을 하고 있음.
Safety and Liveness guarantees
Redlock이 목표로 하는 보장.
- Safety property
- Mutual exclusion.
- 한 번에 한 개의 클라이언트만 락을 소유.
- Liveness property A
- Deadlock free.
- 결과적으로eventually 락의 획득은 언제나 가능.
- 리소스를 잠근 클라이언트가 장애가 나거나 파티션 되더라도(split brain을 말하는 게 아닐까).
- Liveness property B
- Fault tolerance.
- 대다수의 레디스 노드가 살아있기만 한다면, 클라이언트는 락을 획득하고 풀 수 있음.
why failover-based implementations are not enough
페일오버 기반의 구현(대부분의 DLM 방식)이 왜 충분치 않은지.
// 잠금 획득 (NX: 기존에 존재하지 않는 키라면, PX: 만료 설정)
SET resource_name my_random_value NX PX 30000
// 잠금 해제
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
- 리소스 잠금을 위해 한 인스턴스에서 키를 생성.
- TTL도 함께 설정. 클라이언트에 문제가 있더라도 결국에는 락을 해제하기 위함. liveness property A.
- 리소스 잠금 해제 시에는 키를 삭제.
- SPOF가 되지 않기 위해 레디스 리더/팔로워(페일오버) 구성 필요.
- 하지만, 데이터 복제는 비동기로 이뤄짐.
- 복제가 이뤄지기 전에 리더가 죽으면, safety property 위반 가능.
The Redlock algorithm
이 알고리즘의 분산 버전에서는 N개의 레디스 마스터가 있다고 가정함. 각 노드들은 모두 독립적이며, 리플리케이션이나 암묵적 코디네이터 시스템을 사용하지 않음. SPOF를 피하기 위해 여러 인스턴스를 사용하면서도, 비동기 리플리케이션으로 인한 safety 위반도 피하는 것. 또한, liveness를 위해 정족수quorum 사용.
- 현재 시간을 구함.
- N개의 인스턴스들에게 차례로 같은 키(그리고 랜덤 값으로)에 대한 락 획득 시도. 획득에 대한 타임아웃은 잠금의 자동 해제 시간보다 작아야 함. 레디스 노드가 장애인 상황에서 클라이언트가 블럭킹 된 상태로 오랫동안 남아 있는 것을 막아줌. 인스턴스가 이용 불가라면 빠르게 다음 인스턴스와의 대화 시도.
- 클라이언트는 얼마나 많은 시간을 잠금 획득에 쏟았는지를 계산. 2번이 완료된 시간에서 1번에서 구한 시간을 빼면 됨. 과반수 이상으로부터 잠금을 획득했고, 획득 소요시간이 잠금 유효 시간보다 작다면, 락을 획득한 걸로 간주.
- 잠금이 획득됐다면, 잠금 유효 시간은 초기의 유효 시간에서 획득 소요 시간을 뺀 값이 됨.
- 만약 어떤 이유로든 잠금 획득에 실패했다면, 모든 인스턴스로부터 잠금 취소를 시도.
07/19
Distributed locks with Redis #2
https://redis.io/topics/distlock 추가 정리.
Is the algorithm asynchronous?
이 알고리즘은 아래의 가정에 기반.
- 프로세스들 간에 동기화된 클럭은 없더라도,
- 모든 프로세스에서의 로컬 타임은 대략적으로 같은 속도로 흐른다고 가정.
- 잠금의 자동 릴리즈 시간에 비해 적은 오차를 허용.
따라서, mutual exclusion 규칙을 좀 더 정확하게 명시할 수 있음.
잠금을 획득한 상태의 클라이언트가 ‘잠금 유효 시간에서 약간(프로세스 간의 클락 드리프트를 보상하기 위한 몇 ms 정도)을 뺀 시간’ 내에 작업을 끝내는 경우에 한해서만 mutual exclusion을 보장.
어떻게 보면 당연한 이야기.
Retry on failure
클라이언트가 잠금을 획득할 수 없을 때, 임의의 지연을 두고 재시도를 해야 함. 이유는 아래와 같음.
in order to try to desynchronize multiple clients trying to acquire the lock for the same resource at the same time (this may result in a split brain condition where nobody wins)
원문을 그대로 적은 것은 ‘desynchronize multiple clients’의 정확한 의미를 모르겠기 때문. 보통, 경합상태에 빠져 예외가 발생했을 때, 서로 즉각 재시도를 하면 다시 경합상태에 빠지게 됨. Redlock 처럼 정족수quorum를 사용하는 경우, 반복적으로 아무 승자도 없는 split brain이 발생하게 될 것. 그래서 임의의 지연을 두고 재시도를 하게 되는데, 아마도 이를 얘기하는 것으로 보임.
한편, 클라이언트는 멀티플렉싱을 이용해서 N개의 인스턴스에 대해 동시에 SET 커맨드를 보내야 함.
- 다수의 레디스 인스턴스에 대해 잠금을 빠르게 획득하면 할수록,
- split brain 조건이 발생할 가능성이 줄어들기 때문.
Safety arguments
이 알고리즘은 safety(mutual exclusion)를 만족시킬까?
- 한 클라이언트가 다수의 인스턴스에 대해 잠금을 얻었다고 가정.
- 모든 인스턴스들은 같은 키와 함께 같은 TTL을 가졌으나,
- 서로 다른 시간에 키가 설정 되었으니, 만료도 서로 다른 시간에 이뤄질 것.
- 첫 번째 키가 T1 시간에 저장되고, 마지막 키가 T2 시간에 저장 되었다면,
- 첫 번째 키는 적어도
MIN_VALIDITY=TTL-(T2-T1)-CLOCK_DRIFT동안 유지. - 수식이라 헷갈릴 수 있는데 그림 그려보면 당연한 이야기.
- 그리고 다른 키들은 이것보다 늦게 만료.
- 따라서, 적어도
MIN_VALIDITY동안은 키들이 동시에 유지됨. - 다수의 키들이 설정되어 있는 이 시간 동안, 다른 클라이언트는 잠금을 획득할 수 없음.
- 이미 N/2 + 1 키들이 이미 존재하므로, N/2 + 1개의 SET NX 연산이 실패하기 때문.
- 따라서, 잠금이 이미 획득되어 있는 동시에 다시 획득되는 일은 불가.
07/21
Distributed locks with Redis #3
https://redis.io/topics/distlock 정리 마지막.
Liveness arguments
liveness는 아래 3가지 특성에 기반함.
- 자동 잠금 해제release(키 만료에 의한). 결국 키들은 다시 잠금에 사용된다.
- 클라이언트는 잠금에 실패했거나(부분적인 성공을 말하는 듯), 잠금을 획득한 뒤 작업을 끝내면, 잠금을 제거함. 이는 잠금을 다시 얻기 위해 키 만료를 기다릴 필요가 없도록 도와줌.
- 클라이언트가 잠금을 재시도 해야 할 때, 다수의 잠금을 획득하는 데 걸리는 시간보다 좀 더 긴 시간을 기다림. 자원 경합 동안 split brain이 발생할 확률을 줄이기 위함.
하지만, 네트워크 파티션이 일어났을 때는 TTL 만큼의 가용성을 포기해야 함. 만약, 연속적인 파티션이 일어난다면, 그만큼 가용성 페널티는 늘어남.
나머지 기록은 특별한 것이 없어 생략. 결국, 당연한 이야기를 하고 있으며, 또 한가지 의문이 드는 것은, 레디스 클러스터 구조에서도 리더-팔로워 구성이 이뤄지는데, 이 알고리즘은 결국 사용할 수 없는 것 아닌가 함. 혹은 잠금을 위해 멀티 리더 구성을 따로 가져가야 하나? Redisson 라이브러리 구현체를 통해 이를 좀 더 살펴보기로.
Redlock의 아쉬움
- 결국, 리플리케이션이 없는 멀티 리더 방식을 전제로 하고 있음.
- 리더-팔로워를 기반으로 하는 레디스 클러스터 방식에서는 사용 불가(그리고 리플리케이션은 비동기).
- 이상해서 좀 더 찾아보니, Redlock 구현체를 제공하던 Redisson에서도 3.12.5 버전에서는 deprecated 됨.
- 이게 그 deprecated 이슈.
- 내용 읽어보면 역시나 비동기 리플리케이션 문제를 지적.
- 대신, RLock을 쓰라고 함. 이는 레디스 3.0에서 제공하기 시작한 WAIT 커맨드를 이용.
- 이 글에서는 Redlock을 poor choice 라고 비판. (참고로, DDIA 도서 저자)
07/24
Spring AMQP Resilience
- 여기에 간단히 정리.
- 프로토콜 에러나 브로커 장애 시의 대응과 비즈니스 예외에 대한 대응을 나누어 설명.
07/27
Spring AMQP Connection and Resource Management
07/28
Spring AMQP Connection and Resource Management
08/02
HackerRank
- Reverse a doubly linked list에 대한 Kotlin 풀이
- 하지만 실패. 동일한 코드를 Java 버전으로 작성했더니 통과.
- 그 동안 이런 문제가 잦아서 오늘부로 결심. HackerRank는 이제 풀지 않음.
08/03
Redis Data Types
08/04
Redis Data Types
08/09
An introduction to Redis data types and abstractions
08/12
An introduction to Redis data types and abstractions
08/13
마이크로 서비스 패턴
7장 마이크로서비스 쿼리 구현 내용 간단 정리. Pattern: API Composition 함께 참고.
- 하나의 DB에서 JOIN SELECT 하던 것이 여러 서비스와 DB로 나뉨.
- 각 프로바이더provider 서비스를 조합하는 API 조합기composer가 필요.
- 그러면서 2가지 설계 이슈가 떠오름.
- 첫 번째로, API 조합기 역할은 누가 담당해야 하는가?
- 앱과 같은 클라이언트가 담당.
- 방화벽이나 네트워크의 속도로 비실용적.
- 서비스 추가나 제거 등의 변경에도 취약.
- API 게이트웨이에 적용.
- 네트워크 측면에서 효율적.
- 하지만 조합 로직의 재사용 어려움.
- standalone 서비스로 구현.
- 네트워크 효율적.
- 재사용성 증대.
- 복잡한 조합에도 유리.
- 운영 등의 부담은 증가.
- 앱과 같은 클라이언트가 담당.
- 두 번째로, API 조합의 단점을 어떻게 극복할 수 있을지?
- 오버헤드.
- 한 번의 DB SELECT로 되던 것이,
- 여러 번의 SELECT와 더불어 API 호출까지 일으킴.
- 리액티브 프로그래밍 모델의 고려.
- 가용성 저하.
- 1개의 서비스 가용성이 0.95 였다면,
- N개의 서비스로 나뉘었을 때는 0.95^N이 됨. (AND 조건이므로)
- 응답을 캐시해 두었다가 API가 불능일 때 사용할 수도.
- 혹은, 미완성된 데이터 그대로 반환하는 것.
- 데이터 일관성 결여.
- DB의 ACID를 사용할 수 없으므로,
- 데이터의 일관성이 깨지기 쉬움.
- 이로 인해 많은 가정들이 생겨나고 코드가 복잡해짐.
- CQRS 등의 방식 고려.
- 오버헤드.
- 나머지는 다 CQRS 이야기.
- 여러 프로바이더의 제공 결과를 인메모리 조인하는 비효율 극복.
- 프로바이더 자체적으로 구현이 어려운 DB의 제약 등을 극복.
- 예컨대, 특정 지역의 음식점 목록 제공 같은 경우는 지리 특화된 DB가 필요할 수도.
- 관심사의 분리. 프로바이더에게 맞지 않는 쿼리 역할과 데이터 관리를 부여하지 않아도 됨.
- 그리고 방법 이야기. 일반적인 내용이라 기록 생략.
- 한편, CQRS의 단점도 언급.
- 아키텍처가 복잡해짐.
- 복제 지연replication lag를 감안/처리해야 함.
An introduction to Redis data types and abstractions
08/14
An introduction to Redis data types and abstractions
- First stpes with Redis Lists
- Common use cases for lists
- Capped lists
- Blocking operations on lists
- Automatic creation and removal of keys
일단, 리스트에 대한 내용은 여기까지가 마지막.
08/15
An introduction to Redis data types and abstractions
08/23
An introduction to Redis data types and abstractions
08/24
An introduction to Redis data types and abstractions
08/25
An introduction to Redis data types and abstractions
08/31
HTTP 완벽 가이드
09/07
HTTP 완벽 가이드
캐시에 대한 내용.
09/09
HTTP 완벽 가이드
09/15
HTTP 완벽 가이드
09/16
HTTP 완벽 가이드
09/17
HTTP 완벽 가이드
09/23
LinkedList - Two Pointer Techinique
- 연결 리스트 순회를 2개의 포인터로 할 수 있음.
- 코딩 인터뷰 완전 분석에서는 runner 기법이라 소개했음.
- 이를 이용하면, 한 번의 순회로 연결리스트의 절반이 어디인지 알아낼 수 있었음.
- 그리고 LeetCode에서는 Two Pointer Technique라고 소개.
- 이를 이용해 연결리스트에 순환cycle 있는지를 알아낼 수 있음.
- 코드도 간단히 작성해 봄.
- 이번엔 두 번째 문제인 Linked List Cycle II.
- 이것 저것 그림 그려보다가 되는 방법을 찾았는데 증명은 아직 못함.
09/24
LinkedList - Two Pointer Technique
- 어제의 문제 증명은 한참 고민 후 결국 구글링.
- 여기 그 설명이 잘 나와 있음.
- 문제 풀이와 증명을 이해해 가는 과정은 충분히 재밌었음.
- 그러나 그 이상의 의미에 대해서는 물음표.
09/25
LinkedList - Two Pointer Technique
- 오늘은 Intersection of Two Linked Lists.
- 간단히 구현해 봄.
- 그리고 LeetCode Solution을 보고 좀 더 개선.
- 설명은 여기가 잘 되어 있음. 그림도 같이.
- 관련해서 배열 교집합은 어떻게 구하는지 궁금하여 찾아봄.
09/28
LinkedList - Classic Problems
- 오늘은 LinkedList의 Classic Problems 부분.
- 일단 Reverse Linked List 풀이.
- 다음은 Remove Linked List Elements 풀이.
- Odd Even Linked List 풀이.
- Palindrome Linked List 풀이
- 여러 노드를 동시에 트랙킹하기 위해 여러 개의 포인터를 두기도 함.
- 현재 노드 앞 노드를 알아야 하기도. 하지만 단방향 연결 리스트는 다음 노드만 알 수 있음. 따라서 별도 저장 공간에 이전 노드를 저장하기도.
09/29
Doubly Linked List
- LeetCode Linked List 컨텐츠의 마지막 내용인 DLL.
- 간단히 구현해 봄.
- 그리고 여기 GeeksForGeeks 문서에 DLL의 장단점이 잘 나와 있음.
- DLL은 양방향 순회가 가능하고, 삭제 연산이 좀 더 효율적이며, 주어진 노드의 앞으로 바로 삽입 가능.
- 한편, DLL은 추가 저장 공간을 필요로 함. 또한 이를 관리하기 위한 부가적 코드도 수반.
- 마지막으로 아래 그림은 여기서 보여주는 각 자료구조 연산의 시간 복잡도 비교.

Linked List 관련 문제
- Conclusion 부분에서 몇 가지 문제가 더 있는데 그 중 2가지를 구현.
- 하나는 Merge Two Sorted Lists.
- 다른 하나는 Add Two Numbers.
© 2020 codehumane ― Powered by Jekyll and Textlog theme